


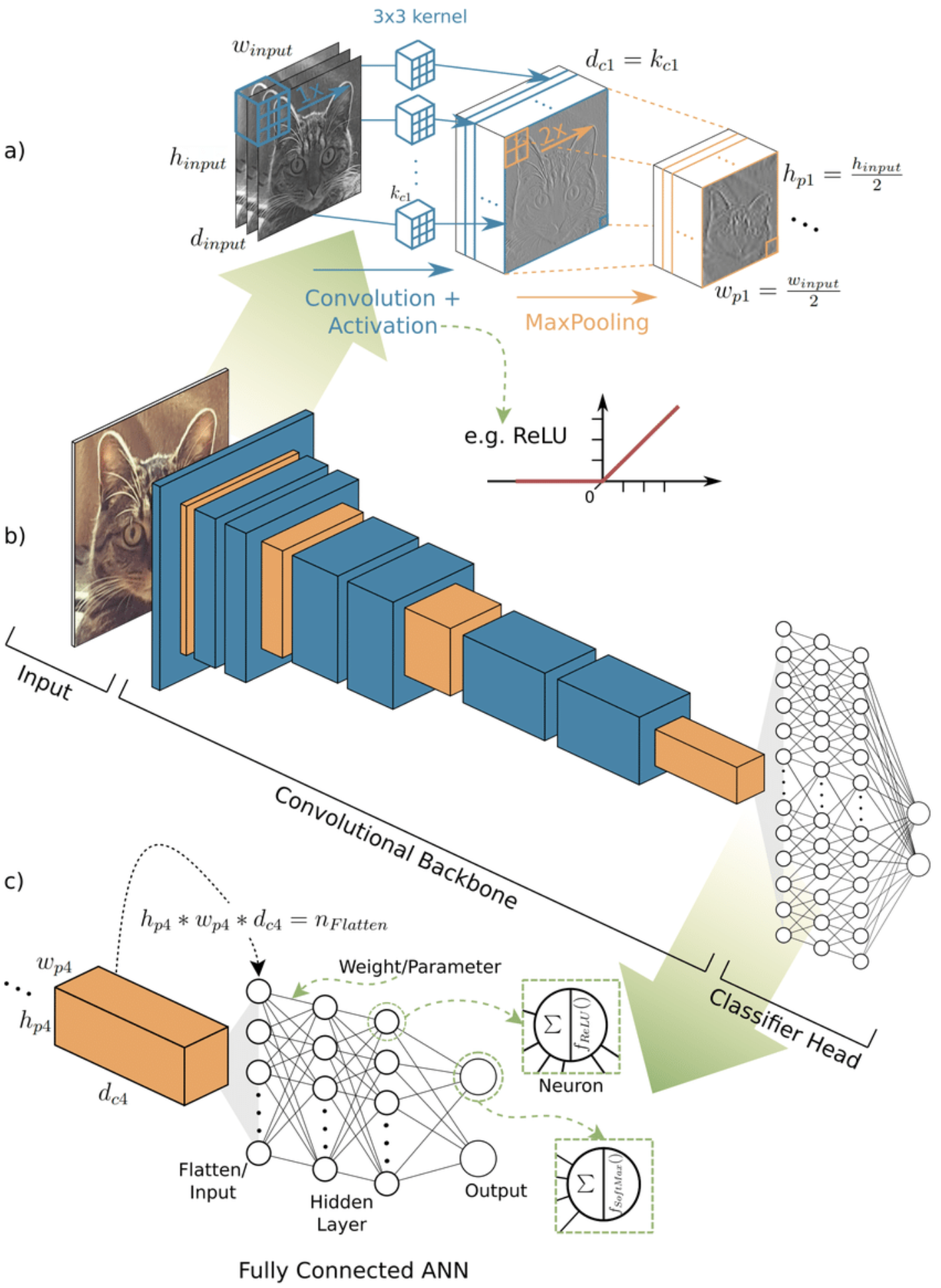
Besoin produit
La société YOMY a contacté Adaly afin de concevoir l’IA embarquée du robot YOMY, un distributeur connecté de croquettes et de pâté pour chats. Equipé d’une caméra embarquée, ce robot devait être capable de détecter la présence d’un chat dans son flux vidéo, mais aussi de différencier plusieurs chats d’un même foyer, afin de rendre possible une alimentation différenciée et suivie par l’utilisateur depuis une application mobile, élément essentiel de la proposition de valeur de notre client.
Recherche et développement
Adaly a conçu et développé des modèles de vision adaptés au besoin, après une phase approfondie de recherche scientifique et de préparation des données. Sur la base d’architectures à la pointe de la recherche scientifique et en combinant plusieurs approches telles que les réseaux siamois, les chaînes de modèles ou le fine-tuning, nous avons développé un modèle capable de différencier plusieurs chats d’un même foyer avec un taux de précision dépassant les attentes de YOMY.
Enjeux de déploiement
Afin de tenir compte des contraintes du matériel embarqué dans le robot - microprocesseur et mémoire en particulier -, nous avons collaboré étroitement avec le prestataire de YOMY en charge de sa fabrication, afin de dimensionner nos modèles et d’optimiser leur précision et leur temps d’inférence en embarqué.









